인공지능(AI) 시대를 대비하기 위한 글로벌 IT업체들의 경쟁이 치열하다.
PC 시대에는 중앙처리장치(CPU)가, 모바일 시대에는 애플리케이션프로세서(AP)가 프로세서 시장을 장악했다. 하지만 AI 시대에는 기존 프로세서만으로는 한계가 있어 각 업체들은 저마다의 해법으로 대응 중이다.
CPU, GPU의 한계
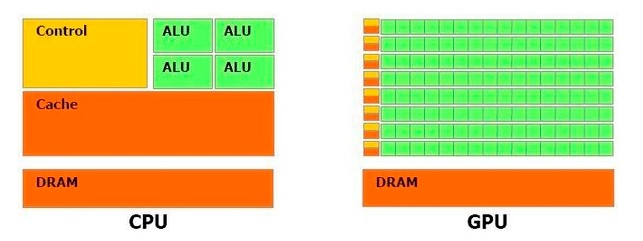
CPU는 코어 당 ALU가 1개씩 붙어 있다. 명령어 입력 순서대로 미리 데이터를 가져와 내부 캐시 메모리에 임시로 저장, 하나씩 처리한다. GPU는 내부 캐시 메모리 비중이 크지 않아 처리 속도가 느린 대신 코어 당 수백~수천개의 ALU가 탑재돼있어 단순한 명령어 여러 개를 동시에 처리할 수 있다.
옥타(8)코어 CPU가 속도가 빠른 8대의 비행기로 짐을 실어 나른다면, GPU는 수백~수천대의 기차로 짐을 한 번에 옮기는 셈이다.
여기에 CPU는 대개 정수나 고정소수점(부동소수점) 데이터가 많이 활용되는 인터넷 서핑, 문서 작성 등의 작업에 최적화돼 설계돼있지만 GPU는 3차원(3D) 그래픽 등 한 번에 수많은 데이터를 처리해야하는 멀티미디어를 연산할 수 있게 만들어진다.
AI의 경우 방대한 양의 데이터를 시시각각 처리, 영상 및 음성 등 멀티미디어로 내보내야 한다. CPU로 가동하기에는 한번에 처리해야하는 데이터의 양이 과다하고, GPU로 가동하기에는 발열량이 많아 연산 처리의 효율성이 떨어진다.
서버용 AI 반도체, FPGA·NPU·GPU 삼파전
AI가 먼저 도입된 서버 시장에서는 GPU와 프로그래밍이 가능한 반도체(FPGA), 그리고 NPU 등 주문형 반도체(ASIC)가 삼파전을 벌이고 있다.
GPU가 완성된 그림이라면 FPGA는 밑그림이 그려진 종이로, 업체의 입맛에 따라 색깔을 칠할 수 있다. ASIC은 업체 특성에 맞게 밑그림부터 채색까지 한다.
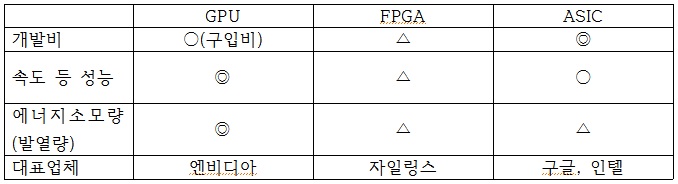
가장 먼저 AI에 나선 업체는 GPU 시장 강자 엔비디아(Nvidia)다. 엔비디아의 고성능 GPU는 기본적으로 고화소 그래픽 처리와 복잡한 과학적 계산에 특화됐다. 개발비 없이 제품을 사 적용만 하면 돼 상당수의 서버 업체들이 AI 서비스 도입을 위해 엔비디아의 GPU를 선택했다.

하지만 효율성이 떨어진다. AI는 크게 ‘학습(딥 러닝)’과 ‘추론’(서비스) 단계로 나뉘는데, 추론의 경우 FP16비트(16비트 정밀도로 고정소수점 데이터를 연산하는 것) 정도의 회로로도 충분히 구현된다.
엔비디아의 GPU는 FP32비트 이상 고정밀도 회로 영역이 전체 프로세서의 절반 이상을 차지한다. 슈퍼컴퓨터, 자율주행차 AI처럼 정확하게 데이터를 ‘학습’해야 하는 시스템을 개발할 때는 적합하지만, ‘서비스’를 제공할 때는 전력소모량이 필요 이상으로 많아 유지비가 많이 든다.
업계 관계자는 “실제 엔비디아의 GPU로 AI를 도입한 서버 업체들은 냉각(Cooling)에 애를 먹고 있다”며 “GPU가 AI 시스템을 개발할 때는 유용하지만 AI 서비스를 구현할 때 쓰이기에는 효율성이 낮다”고 설명했다.
GPU처럼 가속화에 특화된 반도체 중 하나로 주목 받는 게 프로그래밍이 가능한 반도체(FPGA)다. 자일링스가 대표적이다. FPGA는 ASIC이나 GPU보다 초기 개발 비용과 전력소모량이 적다. 하지만 작업 처리 속도가 느리고 복잡한 프로그램을 넣기에는 한계가 있다.
때문에 업계는 FPGA가 특정 상황에 따라 출력 값을 계산해 서비스를 제공하는 ‘추론’에는 적합하지만 즉각적으로 많은 데이터를 처리해야하는 ‘학습’이나 다양한 AI기능을 제공하는 데는 적합하지 않다고 평가한다.
ASIC을 선택한 업체는 구글과 인텔이다. ASIC은 초기 개발 비용이 높지만 용도에 따라 회로 구성이 최적화돼 속도가 빠르고 에너지 효율도 높다.

구글은 지난해 추론 기능이 담긴 1세대 ‘TPU(Tensor Processing Unit)’를 선보이고 데이터 기반 서비스와 데이터센터에 적용하기 시작했다. 지난 5월 ‘클라우드 TPU’로 2세대 제품을 선보였다. 클라우드에 AI를 도입, 학습과 추론을 동시에 할 수 있도록 했다.
PC시대의 1인자였던 인텔도 나섰다.
인텔은 지난해 인수한 AI 스타트업 ‘너바나시스템즈’를 중심으로 별도의 AI 전용 프로세서를 개발, 지난 10월 서버용 시장을 목표로 ‘너바나 NNP(Nervana Neural Network processor)’를 공개했다. 캐시메모리 없이 프로세서에 메모리를 탑재, 데이터에 빠르게 접근할 수 있게 했고 숫자 처리 방식도 바꿨다고 인텔 측은 설명했다.
업계에서는 인텔이 2015년 인수한 알테라의 FPGA 기술을 너바나 NNP에 결합해 성능을 높일 것이라고 내다봤다.
모바일 기기 AI, AP에 내장
스마트폰이나 가전 등 소비자용 기기에서의 AI는 대부분 데이터를 단말기에서 수집, 서버(클라우드)로 보내 학습·추론해 결과값을 기기로 다시 전송하는 방식으로 구현된다.
하지만 데이터가 오가는 과정에서 지연시간(Latency)이 생기고 정보가 유출될 가능성이 있다. AI 기능이 복잡해질수록 데이터 트래픽이 급증하는 것도 단점으로 꼽힌다.
이에 기기 내부에서(온디바이스, On-device) AI 관련 데이터를 수집·처리하는 신경망처리장치(NPU)가 등장했다. 서버처럼 별도의 칩을 부가적으로 더하는 방식이 아닌, 애플리케이션프로세서(AP) 내 NPU 회로를 그려넣는다.
업계 관계자는 “아직 모바일 기기에서 AI는 음성인식 등 비교적 간단한 기능만 쓰여 서버처럼 별도 하드웨어로 NPU를 탑재하지는 않는다”며 “AI 기능이 복잡해지더라도 적용되는 기기 자체가 작으니 지금처럼 AP 내부에 그려 넣되 미세 공정을 활용하는 방식으로 진화할 것”이라고 내다봤다.
퀄컴은 지난 2015년 ‘제로스(Zeroth)’라는 이름의 별도 NPU 설계구조를 발표한 뒤 AP 내부에 적용하고 있다. 자체 뉴럴프로세싱엔진(NPE) 알고리즘을 적용해 상황에 따라 CPU와 GPU, 디지털신호처리프로세서(DSP) 등 기존 AP에 내장된 코어가 선택 가동될 수 있게 해 기능 가동 시 효율성을 높였다.

화웨이도 가세했다. 화웨이는 지난 9월 IFA(국제 가전 박람회) 2017에서 AI용 NPU을 AP 내부에 설계한 ‘기린970’을 공개했다. 중국 AI 전문 기업 ‘캠브리콘’이 핵심 기술을 공급했다.
애플이 뒤를 이었다. ‘아이폰X’에 탑재된 AP ‘A11 바이오닉’에 NPU 영역을 더했다. 머신 러닝, 안면 인식 등의 기능에 특화돼있다. 삼성전자도 AP ‘엑시노스’ 시리즈에 NPU를 더하는 기술을 연구개발(R&D), 양산 모델에 적용 가능한 수준까지 도달한 것으로 알려졌다.
업계 관계자는 “아직 모바일 시장에서 어떤 AI 기능들이 활용될 지 몰라 NPU 개발을 완료한 업체들도 양산 제품에 적용하지 않고 있다”며 “향후 AI 활용도가 높아지면 NPU를 적용한 모델이 프리미엄 스마트폰 시장의 대부분을 차지할 것”이라고 전했다.