장기기억 인공지능(AI) 및 반도체 통합 솔루션 전문기업 디노티시아(대표 정무경)가 고성능 대형언어모델(LLM) ‘DNA 2.0’을 25일 발표했다.
이 모델은 단순 텍스트 생성형 AI를 넘어 다양한 외부 도구를 자동으로 연동해 활용할 수 있는 ‘에이전틱(Agentic) AI’ 실현을 목표로 한다.
‘DNA 2.0’은 사용자의 명령을 이해하고 검색·요약·계산 등의 작업을 수행할 수 있는 ‘툴 콜링(Tool Calling)’ 기능을 크게 강화했다. 특히 한국어 기반 명령어에 최적화된 후처리 체계를 통해 명령 구조와 응답 형식을 정제함으로써 보다 정확하고 일관된 응답을 제공한다.
디노티시아는 MCP(Model Context Protocol) 호환 구조를 적용해 사용자의 자연어 명령을 내부 명세에 따라 자동 변환하고 외부 툴 API와 연결되도록 설계했다. 이를 통해 한국어 기반 질의응답(RAG), 페르소나 설정 등 에이전트 실행 환경에 필수적인 기능들이 고도화됐다.
모델은 0.6B 경량형부터 235B 전문가 혼합(MoE) 기반의 모델까지 다양한 파라미터 라인업으로 구성된다. 고성능 모델에는 문맥에 따른 전문가 모듈만을 활성화하는 MoE 구조를 도입해 연산 효율을 높였으며, ▲14B 모델은 오픈소스로 공개 ▲경량형 모델은 온디바이스 환경 대응을 고려해 최적화됐다.
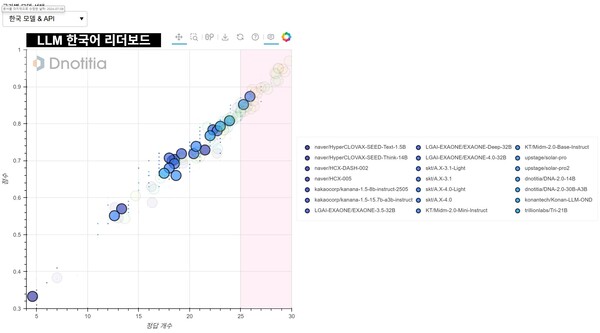
또 디노티시아는 LLM들의 한국어 기반 성능을 객관적으로 평가할 수 있는 벤치마크를 만들어 ‘LLM 한국어 리더보드’ (https://leaderboard.dnotitia.com/)를 오픈했다. 자체 구축한 한국어 중심 평가 데이터셋을 기반으로 다양한 상용 모델 및 오픈소스 모델들을 동일한 조건에서 비교 테스트해 LLM의 한국어 처리 능력을 객관적으로 평가할 수 있도록 했다. 이번에 공개하는 DNA 2.0모델은 본 리더보드를 통해 파라미터 규모가 유사한 국내 모델들 중 가장 뛰어난 성능을 보이기도 하였다.
한편 디노티시아는 지난해 DNA 1.0을 시작으로 국내 최초의 한국어 논리 추론 특화 모델 ‘DNA-R1’을 포함해 이번까지 총 세 차례에 걸쳐 LLM을 공개했다. 이와 함께 AI 양자화 알고리즘 평가 도구 ‘QLLM-INFER’, 다국어 환경에서의 응답 오류를 줄이는 후처리 도구 ‘Smoothie Qwen’ 등을 오픈소스로 공개하며, 국내외 생성형 AI 커뮤니티의 기술 확산과 생태계 활성화를 선도하고 있다.