MLPerf, 올해부터 MLCommons가 주최
전력 측정⋅알고리즘 보완 필요
그래프코어⋅그록⋅하일로 결과 주목
AI(인공지능) 반도체 업체들의 '수능시험'으로 불리는 MLPerf가 이번 분기 평가 마감을 앞두고 있다. 세계 최고 권위의 AI 벤치마크 대회인 MLPerf는 올해부터는 새롭게 출범한 MLCommons에 의해 주최된다. 엔비디아⋅인텔 등 세계적인 반도체 업체들이 대부분 참가한다.
MLPerf는 AI 반도체 벤치마크가 난립하던 시장에서 비교적 객관적인 지표로 평가받는다. 하지만 여전히 신뢰성을 담보하기에 보완해야 할 점도 많다. 올해로 4년 차를 맞는 MLPerf의 의미와, 업계가 주목하는 기업들을 살펴본다.

MLPERF, TOPs 신뢰성 보완하는가
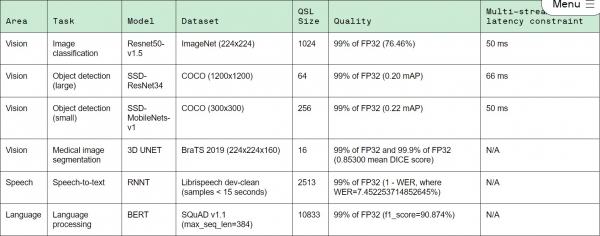
MLPerf는 특정 딥러닝 시나리오를 주고 이에 대해 AI 성능을 평가한다. 이미지 분류⋅사물 탐지⋅강화 학습⋅언어번역 등 시나리오를 제시한다. 정확도 역시 유지해야 한다. 예컨대 특정 알고리즘을 주고 무작위로 여러 번 반복해도 같은 결과가 나오는지, 99% 이상 정확도를 가지는지 등 까다로운 참가 조건을 제시한다.
이렇게 까다로운 조건을 제시한 후에 MLPerf가 묻는 것은 단 하나다. 특정 알고리즘에 대한 1초당 샘플 처리 수다. 칩별로 벤치마크 점수를 기록하지도, 칩별 TOPs(Tera Operations Per Second)를 묻지 않는다.
MLPerf는 왜 TOPs를 묻지도 따지지도 않을까.
AI 반도체 회사들이 등장하면서 자사의 높은 성능을 자랑하는 업체들이 난립했다. 대표적인 것이 TOPs다. TOPs는 쉽게 말해 한 개의 칩 속에 트랜지스터를 많이 넣어뒀다는 의미다. 트랜지스터는 전류를 흐르게 하거나 막아 칩이 데이터를 처리하는 방식을 제어한다. 계속해서 집적도는 높이고 크기를 줄이는 방향으로 발전하고 있다.
하지만 100억개⋅200억개 트랜지스터가 들어가는 AI 반도체는 단순히 트랜지스터 수로만 평가할 수 없다. 한 회사의 직원이 100명인 것과 그 회사 내 효율적으로 일하는 직원이 몇 명인가는 다른 차원의 문제다.
TOPs는 칩 크기가 커지고, 트랜지스터를 많이 넣으면 자연히 높아진다. 물론 트랜지스터를 넣는 것도 쉬운 일은 아니지만, 더 중요한 것은 수백억 개의 트랜지스터들이 얼마나 효율적으로 일하는가다. 내가 원하는 시나리오⋅워크로드를 수행할 수 있는가가 AI 반도체 성능을 결정짓는 핵심이다.

MLPerf가 제 3자에 의해 공인받은 지표라는 점도 의미있다. 자사가 발표한 성능은 자사에게 유리하게 측정 가능하다. 파레시 카리야(Paresh Kharya) 엔비디아 데이터센터 컴퓨팅 제품 관리 책임자 역시 이 지점을 지목한다. 그는 "각 회사가 자체적으로 밝힌 벤치마크⋅성능 데이터는 신뢰도가 부족하다"며 "측정 기준을 표준화해 객관적으로 비교하는 것이 중요한 이유"라고 밝힌 바 있다.
한 팹리스 업체 대표도 "자동차를 가정한다면 동일한 이동 경로⋅트랙에서 측정해야 객관성이 담보된다"며 "연비가 정말 좋다고 했는데 알고 보니 내리막길에서 기어를 풀고 달린다면 객관적 지표라고 할 수 없다"고 말했다.
MLPerf, 보완해야 할 점은
그렇다고 MLPerf가 완벽한 벤치마크라는 뜻은 아니다. 보완해야 할 점도 많다.
MLPerf는 칩 크기에는 제한이 없다. 회사가 타깃하는 시장⋅제품군별로 칩 크기는 당연히 다를 수밖에 없다. 문제는 칩 크기가 크면 당연히 트랜지스터를 많이 넣고, 성능도 상대적으로 우수하게 나올 수밖에 없다는 것이다. 이에 전력 측정 등을 통해 신뢰성을 보완해야 한다는 목소리가 지속해서 제기돼 왔다.
또 다른 팹리스 업체 대표는 "칩을 1의 사이즈로 만드는 것과 10의 사이즈⋅100의 사이즈로 만드는 것은 성능이 차이가 날 수밖에 없다"며 "칩 크기 자체를 제한할 수는 없기 때문에 전력 측정 등을 통해 보완해야 할 것"이라고 설명했다.
이에 대해 MLCommons 측은 KIPOST가 보낸 이메일 회신을 통해 MLPerf Inference v1.0부터는 전력 측정을 추가할 계획이라고 밝혔다. 데이비드 캔터(David Kanter) MLCommons 전무 이사는 "전력 측정 이슈에 대한 중요성을 공감해 왔다"며 "고객⋅MLPerf 제출자 모두 솔루션 효율성을 더 객관적으로 평가하고 받을 수 있도록, 전력 측정 옵션을 다음 벤치마크부터 추가할 계획"이라고 전했다.
알고리즘 역시 보완이 필요하다.
현재 MLPerf가 제시하는 주요 모델은 MobileNet⋅ResNet이다. 2018년 12월 MLPerf 첫 벤치마크 때 제시됐던 딥러닝 모델이 그대로 유지되고 있다. 매달⋅매년 실시간 변화하는 딥러닝 알고리즘을 쫓아가지 못하고 있다는 지적이 나오는 이유다.
특히 AI 반도체는 단순히 모델을 돌릴 수 있는가가 아니라 얼마나 복잡한 알고리즘을 돌릴 수 있는가도 중요하다.
한 시스템 반도체 스타트업 대표는 “자율주행 등 시장 파이는 계속 크고 있는데 여전히 제시되는 모델은 네트워크 복잡성을 담아내지 못한다”며 “YOLO⋅EfficientNets등 복잡한 알고리즘⋅최신 알고리즘을 보완해 나가야 할 것”이라고 강조했다.
YOLO(You Only Look Once)는 딥러닝을 통한 사물탐지(ObjectDetection) 모델 중 하나다. 한 개의 네트워크에서 탐지를 원하는 물체의 영역(bounding box)와 이름을 표시한다. 탐지 속도⋅정확도가 높다는 평가를 받는다.
EfficientNets(이피션트네트)은 구글 연구원이 지난해 개발한 새로운 유형의 CNN(Convolutional Neural Network) 알고리즘이다. CNN은 얼굴 감지⋅물체 인식에 능숙하지만 일정 지점 이상 정확도 향상에 미흡하다는 지적이 있어 왔다. EfficientNets은 체계적인 튜닝 방법을 제공해 보다 정확한 모델을 보다 쉽게 개발할 수 있는 것이 강점이다.
이에 대해 MLCommons 측은 모델 다양성이 부족하다는 점에 대해 공감하며, 자문위 논의를 거쳐 최신 알고리즘을 추가할 계획이라고 밝혔다. 캔터 전무이사는 "자문위 논의를 거쳐 DLRM⋅3DUnet을 추가한 바 있다"며 "논의 이후 결정되겠지만 YOLO⋅EfficientNets이 추가될 것임을 확신한다"고 밝혔다.

지난 MLPerf 벤치마크부터는 BERT(Bidirectional Encoder Representation from Transformers)⋅DLRM(Deep Learning Recommendation Mode)이 추가됐다. BERT는 가장 복잡한 신경망 모델 중 하나로 대화⋅번역⋅검색 등에 광범위하게 사용되는 자연어 처리 모델이다. DLRM은 온라인 쇼핑 웹사이트⋅소셜 미디어⋅검색 결과에 널리 사용되는 모델이다.
하지만 여전히 스펙트럼이 넓은 AI 반도체의 현실을 모두 담아내지 못한다는 목소리가 나온다. 한 반도체 설계 스타트업 대표는 “AI 반도체는 범용에만 국한되지 않는다. 워낙 니치마켓이 많고, 다양한 알고리즘이 존재한다”며 "현 단계에서는 알고리즘이 워낙 다양하기 때문에 단순히 뭐가 좋다, 나쁘다고 할 수 없는 측면이 있다"고 말했다. 또 다른 시스템 반도체 업체 대표도 "AI 스펙트럼이 너무 넓은 게 문제"라며 "한 분야에서 압도적인 딥러닝 알고리즘이 등장해 그 자체가 범용적이 된다면 의미가 있지만, 현재는 분야가 굉장히 다양하고 실시간으로 변화하는 상황"이라고 밝혔다.
올해 주목되는 기업들은
가장 관심이 쏠리는 분야는 상용화 가능 부분이다.
MLPerf는 상용화 여부에 따라 세 가지 범주로 나뉜다. 상용화 가능(Commercially Available)⋅프리뷰(Preview)⋅연구개발⋅기타(R&D and other) 세 가지다. 상용화 가능은 모든 하드웨어⋅소프트웨어가 서드파티에 의해 시판되거나 사용 중이어야 한다. 프리뷰는 출시되지 않았지만 다음 벤치마크 라운드까지 출시돼야 한다. 지난해까지는 6개월이라는 조건이 있었지만 이번 벤치마크부터 생략됐다. 연구 개발은 이런 기준을 충족시킬 필요가 없다.

단연 관심은 엔비디아다. 엔비디아는 지난해 MLPerf 벤치마크에서 모든 테스트에 상용화 가능 제품을 제출한 유일한 회사였다. 3회 연속 가장 좋은 성과를 낸 바 있다.
엔비디아의 A100 GPU는 8개의 모든 MLPerf 벤치마크에서 가속기 중 가장 빠른 성능을 보여줬다. HDR(하이다이나믹레인지) InfiniBand(인피니밴드)로 연결된 DGX A100 시스템의 대규모 클러스터 'DGX 슈퍼POD(DGX SuperPOD)' 시스템 역시 가장 빠른 시간 기록을 달성, 8개의 신기록을 세웠다. 이번 역시 MLPerf 벤치마크 신기록을 달성할지 관심이 쏠리는 이유다.
AI 반도체 스타트업들의 성적도 주목된다. 업계가 주목하는 스타트업들은 영국 AI 반도체 전문 기업 그래프코어(Grafhcore)⋅미국 반도체 스타트업인 그록(Groq)⋅이스라엘 벤처기업인 하일로(Hailo)다.
그래프코어는 지난해 3월 기준 투자금 4억5000만달러(약5098억5000만원)를 유치해 투자금 부문에서 글로벌 1위 기록했다. 지난해 12월에는 추가로 2억2200만달러(약2515억 2600만원) 투자금을 유치한 바 있다. 하일로는 지난해 AI 칩셋 생산을 위해 6000만달러(약679억8000만원) 자금 조달을 완료한 상태며, 그록 역시 6200만달러(약702억4600만원) 투자금을 유치했다.
하지만 그래프코어⋅그록은 아직까지 MLPerf 벤치마크에 참여하지 않았고, 하일로는 기대보다 낮은 성적을 받은 바 있다. 하일로는 지난 2019년 벤치마크 참여했지만 추론(inference) 등재 기업 중 가장 낮은 성적을 기록했다.

지난해 세 기업 모두 우수한 성능의 칩을 공개한 만큼 이번에 MLPerf에 참여할지, 어떤 성적표를 보여줄지 업계가 주목하고 있다.
하일로는 지난해 하일로-8 AI 가속기를 출시하며, 해당 가속기가 벤치마크에서 인텔과 구글의 추론용 엣지 AI칩을 능가하는 성능을 보여준다고 밝혔다. 그래프코어 역시 자사2세대 IPU(IPU, Intelligence Processing Unit)가 엔비디아 A100보다 월등히 높은 성능을 보였다고 주장했다. 그록 역시 지난해 데이터센터의 AI 추론을 위한 고성능 TSP(텐서 스트리밍 프로세서)를 개발해 서버 시장에 공급하고 있다고 밝혔다.
하지만 업계는 이러한 벤치마크 결과가 각 회사가 자체 기준으로 측정했기 때문에 공신력이 부족하다고 비판해왔다. 만약 이번 MLPerf 벤치마크에 세 기업이 참여해 유의미한 결과를 낸다면 업계 평가는 달라질 것으로 전망된다.
국내 스타트업들 역시 결과에 관심이 모이고 있다. 현재까지 MLPerf 벤치마크에서 공인받은 국내 스타트업은 퓨리오사AI⋅모빌린트(Mobilint)가 유일하다.
퓨리오사AI는 2019년 엔비디아(nvidia)⋅퀄컴(Qualcomm)등 총 13개 기업이 참여한 추론 성능 테스트(MLPerf Inference v0.5)에서 아시아 스타트업으론 유일하게 리스트에 등재됐다. 모빌린트 역시 지난해 추론 성능 테스트(MLPerf Inference v0.7)에 이름을 올렸다.

이번 MLPerf 제출 기한은 3월 중순까지다. 한 달 뒤면 결과가 공개된다. MLPerf 벤치마크는 엔비디아⋅인텔 등 세계적인 기업이 참여하는 NPU(신경망처리장치) 검증 테스트다. 지난 2018년 12월 처음 실시된 이후, 2019년⋅2020년에 이어 이번이 4번째 테스트다.
현재까지 MLPerf 벤치마크 테스트 주기는 일정하지 않았다. MLCommons 측은 지난해 신종 코로나바이러스감염증(코로나19)으로 인해 일정이 중단된 바 있으며 앞으로는 6개월마다 주기적으로 벤치마크를 진행할 계획임을 밝혔다.
한 시스템 반도체 업체 대표는 "올해 MLPerf에 참여하는 AI 반도체 회사들이 쏟아질 것으로 전망된다"며 "지금까지는 제출만으로 의미가 있었지만 앞으로 3년은 AI 반도체 회사들이 정말 성적표를 받는 시험대에 오르는 시점이다. 이번 MLPerf에 업계가 주목하는 이유"라고 밝혔다.
다음은 MLCommons 측 이메일 회신 전문
1. When the size of the chip submitted by each company is different, the performance may vary, but there is no complementary measure for this. I want to know if there is a plan of the complementary measure for this?
First, it’s important to note that MLPerf is a system benchmark. It incorporates silicon chips, as well as compilers, frameworks and many other components. Right now, we require disclosing the number of chips as you mention. Generally, this is a good proxy for total cost. But as you point out, an 800mm2 chip is much more expensive than an 80mm2 chip. Many of our submissions are for commercial systems where you can estimate the system cost.
Starting in our next inference submission, we will have an optional power measurement so that submitters and customers can help to evaluate the efficiency of a solution, which is a major element of total cost.
2. It is pointed out that the diversity of model is insufficient. MobileNet⋅ResNet is still old model. There is a point that it is necessary to see how complex network can be run through YOLO and EfficientNets, etc. I want to know if there is complementary measure for this or a plan?
Absolutely. We are looking at changing our set of benchmarks to reflect what customers want.
We have built advisory boards to get customer influence and help guide what benchmarks we should add and remove. Those customer advisory boards helped us pick out DLRM as a recommendation benchmark and 3DUnet as a medical imaging benchmark. Going forward, we expect to have an advisory board for automotive and also vision. We don’t know what they will recommend, but I’m sure they will consider YOLO and EfficientNets.
3. I want to check the conditions for submitting to 'closed'
Generally, closed submissions require using a model that is equivalent to the reference. It limits the optimizations to ensure that any comparisons are fair and reasonable.
On the other hand, Open submissions can modify the model substantially, which allows for more optimization techniques. For example, in inference the open division allows retraining and sparsity.
4. The cycle of the submission is not regular yet. Do you have any plans for this.
You are absolutely correct. Last year, our schedule was interrupted by COVID-19. Going forward, we have a submission every 6 months. Inference is in 1Q21, training in 2Q21, inference again in 3Q21, and training in 4Q21. Some of the other benchmark suites such as HPC, mobile, and tiny have their own schedules as well.
5. I am curious what exactly means normalized performance. Is it assuming the case of using a silicon chip?
Normalizing is a way of transforming pure performance into a normalized ratio, e.g., performance/chip, performance/watt, performance/$. Not every normalization makes sense. But in the case of performance / chip it gives you a rough idea of what each chip can accomplish.
6. Ml perf hasn't considered electricity yet, do you have any plans?
Absolutely. I’m glad you think this is important, as we have been working on this for a long time! I actually helped to lead the MLPerf Power Measurement group. I’m very excited that we will have power measurement in MLPerf Inference v1.0 - so you will be able to see results soon.