퓨리오사AI, 핵심 프로세서 '퓨리오사 매드런 코-프로세서' 설계 막바지
마이크로 아키텍처 및 소프트웨어 컴파일러 역량으로 2022년 상용화
인공지능(AI) 반도체는 범용화가 어렵다.
수요처가 다양하고 쓰임새도 수만가지며, 알고리즘 유행도 6개월마다 바뀌는 탓에 쉽사리 하드웨어를 특정할 수 없기 때문이다. 그래서 글로벌 반도체 기업은 물론 굵직굵직한 수요 기업들마저 자체 AI 반도체(칩)를 개발한다.
이같은 상황에서도 시장 문을 두드리는 국내 스타트업이 있다. 최근 네이버의 기술 스타트업 액셀러레이터 D2SF, 인텔렉추얼디스커버리 등으로부터 시리즈 A 투자로 80억원을 유치한 퓨리오사AI(대표 백준호)다.
퓨리오사AI가 내년 AI 코어 프로세서 샘플을 내놓는다.
AI 반도체, 수요만큼 요구사항도 많다

최근 AI 업계의 뜨거운 감자는 미국 AI 칩 스타트업 세레브라스시스템(Cerebras system)이 발표한 초대형 AI 칩 ‘웨이퍼 스케일 엔진(Wafer engine Engine)’이었다.
하나에 4만6225㎟ 크기인 ‘웨이퍼 스케일 엔진’에는 1조2000억개의 트랜지스터가 들어있다. 이름처럼 300㎜ 웨이퍼 1장에 하나밖에 만들 수 없다. 보통 서버용 AI 칩은 웨이퍼 장당 100개 정도 나오고, 칩 당 많아봤자 수십억개 트랜지스터가 들어가있다는 걸 감안하면 비교할 수 없을 정도로 크다.
상용화 가능성이 거의 보이지 않음에도 업계가 이 칩에 주목한 이유는 이렇게 큰 반도체가 필요할 정도로 AI 칩에 대한 요구사항이 많기 때문이다.
서버에 들어가는 AI 칩만 해도 음성 인식, 이미지 분석, 추천 등 다양한 기능을 가속화하는 데 쓰인다. 용처에 따라 알고리즘이 다르다보니 칩에 대한 요구사항도 제각각이다. 모든 수요에 맞추려면 성능이 그만큼 높아져야해 칩 사이즈가 커질수밖에 없다.
서버 업계는 100~1000TOPS(Tera operation per second) 성능을 갖춘 고용량 서버용 AI 칩을 원한다. 이걸로도 성능이 만족스럽지 않으니 확장성은 거의 기본 요구사항이 됐다.
여기에 AI 알고리즘은 학습과 추론을 반복하기 때문에 ‘완성’의 개념이 없다. 알고리즘의 틀인 프레임워크조차 6개월마다 한 번씩 대세가 바뀌기 때문에 칩을 서버에 적용하고 난 다음에도 위에 올라간 알고리즘을 수정할 수 있어야한다. 특정 알고리즘에 최적화된(Hardening) 전용 반도체(ASIC)는 오히려 한계가 있는 셈이다.
백준호 퓨리오사AI 대표는 “서버 업계의 요구 사항을 만족하기 위해서는 와트 당 5~10TOPS 성능과 더불어 확장성과 프로그래머블의 두 가지 요소를 모두 갖춘 칩을 만들어야 한다”며 “기존 시스템에 잘 융합될 수 있어야 해 단순 부품이 아닌 시스템적인 관점에서 칩을 설계해야한다”고 말했다.
자신감의 비결, 아키텍처와 컴파일링
퓨리오사AI는 서버 및 자율주행용 딥러닝(DNN) 추론 가속기 보드를 개발한다. 이 보드에는 핵심인 전처리 전용 프로세서가 시스템온칩(SoC) 형태로 탑재되고, AI 코어 프로세서와 메모리 등도 내장된다. 단순히 칩만 설계해서는 승산이 없다는 판단에서다.
상용화는 2022년으로, 내년 삼성전자에서 AI 코어 프로세서인 ‘퓨리오사 매드런 코-프로세서(Furiosa Madrun Co-processor)’ 샘플 칩을 찍을 계획이다. RISC-V 코어 기반 ASIC 업체 세미파이브에서 설계 후반부 작업을 진행 중이다.
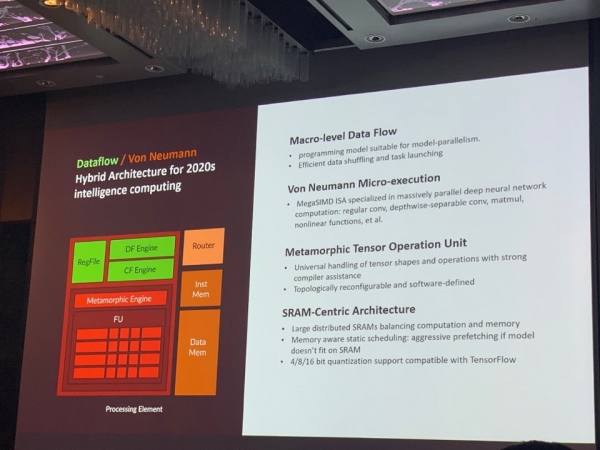
당장 겨냥하는 건 물체 감지 및 예측(4K 60fps), 얼굴 추적 및 3차원(3D) 자세 예측 모델, 센서 융합 모델 시장이다.
백 대표는 “코어 아키텍처부터 시스템 아키텍처, 소프트웨어까지 모든 부분을 만족시켜야 수요 업체들이 요구하는 성능과 효율성을 달성할 수 있다”며 “최대 성능보다는 기존 시스템과 잘 융합돼 최대의 효율성을 뽑아낼 수 있는 가속기를 만드는 게 목표”라고 말했다.
회사는 매드런 코-프로세서를 기능이 특정된 보통의 ASIC과는 다르게 프로그래머블하고, 확장성까지 갖춘 ASIC으로 만들 계획이다. 무기는 인력이다.
통상 팹리스는 RTL 설계 인력이 전체 인력의 대부분을 차지하지만, 이 회사는 마이크로 아키텍처와 소프트웨어 컴파일러 전문가들이 주축이다. 국내에서는 쉽게 찾아볼 수 없는 팀이다. 백 대표 자신도 AMD 그래픽처리장치(GPU) 소프트웨어 설계팀 및 하드웨어 설계팀을 두루 거친 아키텍처 엔지니어다.

얼마 전 프로그래머블반도체(FPGA)로 만든 시제품으로 AI 칩 벤치마크 테스트 ‘MLPerf’의 추론 테스트에 한국에선 유일하게 참여, 퀄컴·엔비디아 등 글로벌 업체들과 겨뤄 좋은 성과를 냈다. 완성된 칩이 나오면 벤치 마크 테스트에서 더 우수한 성적을 낼 수 있을 것이라고 백 대표는 자신했다.
백 대표는 “여러 글로벌 업체들과 논의 중인데 AI 칩 개발만 하고 양산은 하지 않는 업체가 워낙 많은터라 양산 가능성에 대해 의심하는 이들이 많다”며 “이같은 우려를 불식하기 위해서라도 샘플 칩을 내놓고 본격 양산을 준비할 계획”이라고 말했다.