쌓거나 혹은 늘리거나… 가격 낮추는 방안도 관건
오는 2021년 상용화되는 차세대 고성능 메모리 3세대 고대역폭메모리(HBM3) 규격에 대한 논의가 한창이다. 목표는 이전 규격인 2세대 HBM2보다 2배 이상 성능을 높이고, 단가는 낮춰 보다 많은 곳에 쓰일 수 있도록 하는 것이다.
문제는 구현 방법이다.
업계는 D램을 더 쌓을지, HBM3 모듈을 더 많이 집어넣을지에 대해 논의하고 있다. 더 쌓기에는 코어 D램의 두께를 줄여야한다는 점이, 모듈 수를 늘리기엔 주요 고객사의 반응이 마땅찮다는 점이 발목을 잡는다. 2.5차원(2.5D) 패키징 하나뿐이던 후공정(Packaging) 방법도 여럿 대두되고 있다.
밑 그림은 나왔다
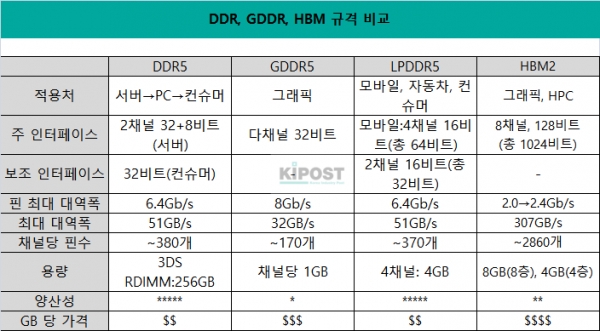
HBM은 D램을 여러 개 쌓아 한 번에 전송할 수 있는 데이터의 용량(메모리 대역폭)을 이전보다 크게 늘린 메모리다.
반도체에서 데이터를 주고 받는 통로인 입출력(I/O)을 수 천개 뚫어 반도체 간을 연결하는 실리콘관통전극(TSV) 기술이 필요하고, 다른 논리(Logic) 반도체와 함께 패키징돼 특수 기판인 인터포저(Interposer)가 쓰인다.
아파트를 예로 들면 실리콘 인터포저(필로티) 위에 로직 칩(커뮤니티센터)와 D램(각 세대)들이 적층되는 형태다.
지금까지 HBM은 인공지능(AI), 고성능컴퓨팅(HPC) 시장에 주로 활용됐다.
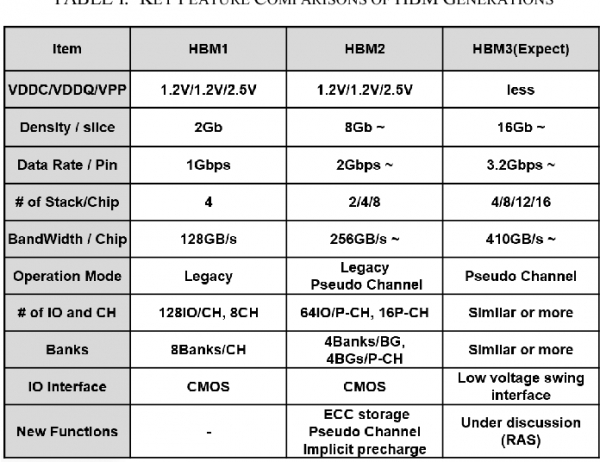
HBM3의 성능은 현재 HBM2의 2배 이상이 될 전망이다. 지난 2017년 국제전기전자학회(IEEE) 국제메모리워크샵(IMW)에서 전망한 HBM3의 대역폭은 410GB/s 이상이다. 적층 수는 많게는 HBM2의 2배다. 지난해 말 국제반도체표준협의기구(JEDEC)의 HBM 규격 개정으로 현재 HBM2는 D램 최대 12개를 쌓아 만들 수 있다.
쌓을 것인가 늘릴 것인가, 그것이 문제로다
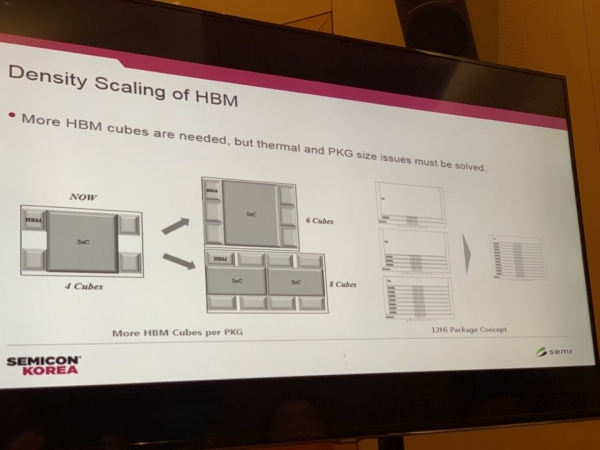
이 성능을 어떻게 구현할 수 있을까.
먼저 HBM을 구성하는 D램 칩은 20나노 8Gb D램에서 10나노대 16Gb D램으로 바뀐다. HBM2에서는 8Gb D램을 12개 쌓아 최대 24GB짜리 모듈을 만들었다. HBM3에서는 16Gb D램을 16개 쌓아 32GB 모듈을 만들 수 있다.
D램을 더 많이 쌓으면 두께도 그만큼 늘어나는데, 완성품(OEM) 업체들은 이를 달가워 하지 않는다. 코어 D램 두께를 줄이기도 쉽지 않다. D램은 길쭉한 원통형 커패시터에 전하를 저장해 데이터의 유무를 판단하는데, D램 두께를 줄이면 커패시터 길이도 짧아져 같은 양의 전하를 저장할 수 없다.
대체 방안으로는 낮은 단수의 HBM3 큐브(Cube)를 여러 개 넣어 메모리 용량을 늘리는 것이 논의되고 있다. HBM2에서는 모듈 하나에 최대 4개의 HBM2 큐브가 들어갔는데, HBM3에서는 6개, 8개로 큐브 수를 늘리는 식이다. 하지만 역시 면적이 넓어져야한다는 단점이 있다.
업계 관계자는 “프로세서 업체들은 코어 D램의 두께를 줄여 적층 수를 높이는 방안을 선호하지만 기술적으로 구현하기가 어려울뿐더러 설계 또한 복잡해진다”고 설명했다.
HBM의 가장 큰 장점, 대역폭은 HBM2보다 2배 증가한 512GB/s로 점쳐진다. HBM(128GB/s)에서 HBM2(256GB/s)로 발전할 때도 대역폭은 2배 증가했다.
데이터 대역폭을 넓히려면 데이터가 오가는 칩 당 I/O 수를 늘리고 TSV를 더 많이 만들어야 한다. 하지만 I/O 수나 TSV를 더 많이 형성하기에는 물리적 한계가 있다.
HBM2 속 20나노 8Gb D램 칩 하나의 I/O 수는 5000개가 넘는다. 8개 칩 각각에 5000개씩만 있어도 총 4만개의 구멍을 뚫어야 해 난이도가 높다. 업계가 HBM에서 HBM2로 넘어갈 때 칩 당 I/O 수는 늘리지 않고 핀 당 대역폭 수를 2배(1Gbps→2.4Gbps)로 높였던 이유도 이 때문이다.
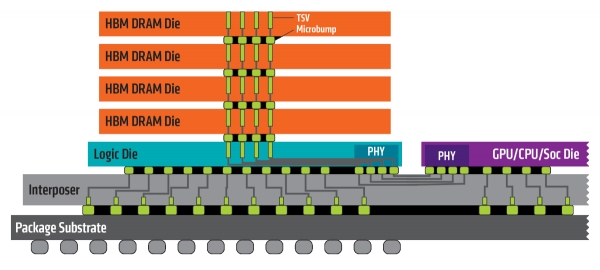
때문에 업계는 배선용 금속 소재나 TSV 공정 기술의 발전이 불가피하다고 설명한다.
후공정 장비 업체 관계자는 “아직 TSV도 열압착(TC) 공정에서 발생하는 불량 등으로 수율이 높지 않은 상태”라며 “핀 당 대역폭을 늘리는 방안이 가장 유력하지만, 근본적으로는 TSV나 배선 소재 개선 등이 더 시급한 문제”라고 말했다.
일상으로 들어오는 HBM3… 가격은?
HBM은 지금까지 AI, HPC 등 서버에 주로 탑재됐다. HBM3부터는 서버에서 PC로, PC에서 일반 소비자 기기로 쓰임새가 넓어진다. 기계학습(ML) 등 인공지능(AI) 기능이 적용된 자율주행차나 가전에는 HBM이 적합하다는 설명이다.
이미 삼성전자는 지난 2016년 ‘핫 칩 컨퍼런스(Hot Chips Conference)’에서 일반 소비자용 HBM의 개념도를 발표했다. 제조사들은 이미 HBM2를 출시하면서 HBM의 영역을 서버에서 PC로 넓혔다.
문제는 가격이다. 8GB HBM2(인터포저 포함)는 개당 175달러(19만6700원)에 달한다. 같은 용량을 GDDR5로 구성했을 때보다 2~3배 비싸다. 코어 D램 칩을 적층하는 TSV 공정이 워낙 어려운데다 실리콘 인터포저 가격 자체가 고가기 때문이다.
손톱만한 반도체 다이 하나만큼의 실리콘 인터포저 가격은 30달러(3만3700원) 정도다. 가로, 세로가 각 1m인 양면 인쇄회로기판(PCB) 원판 가격이 17만원이라는 점을 감안하면 가격 차이가 수배 이상 난다.

삼성이 지난 2016년 HBM3의 대략적인 성능을 발표하면서 일반 소비자용 저가 HBM의 개념을 처음 제시했지만 JEDEC에서 외면 받은 것도 TSV와 인터포저라는 두 가지 한계를 해결하지 못했기 때문이다.
이번에는 조금 다르다. 박명재 SK하이닉스 테크니컬 리더(TL)는 JEDEC에서 HBM3 규격을 여러 시스템에 적용하기 위해 다양한 방안을 검토하고 있다고 설명했다.
박 TL은 “일반 소비자 기기에 AI가 적용되면서 초당 오고가는 데이터의 용량이 기하급수적으로 늘어나고 있다”며 “일반 소비자 기기에 HBM을 적용하기 위해서는 단가를 낮춰야 한다”고 말했다.

레티(CEA-Leti)는 실리콘 인터포저를 그대로 활용하되 배선층(BEoL layer)을 노출시켜 재배선층(RDL)처럼 만들고 TSV를 사용하지 않는 방안과 실리콘 인터포저보다 값싼 유기 인터포저(Organic Interposer)를 활용하는 방안을 저가형 HBM3 패키지 솔루션으로 제시했다.
이 중 현실성이 높은 건 실리콘 인터포저를 쓰되 TSV를 활용하지 않는 방안이다. 이 방안을 활용하면 후공정 작업을 외주 업체(OSAT)에 넘길 수 있다.
반면 유기 인터포저는 대량 양산을 위한 공급망이 조성돼있지 않다. 실리콘 인터포저는 TSV 공정을 진행해야해 TSV 공정으로 HBM을 만드는 메모리 업체들이 자체 조달하지만, 유기 인터포저는 만드는 곳이 몇 곳 없고 물량도 많지 않다.
김구성 강남대 교수는 “실리콘 인터포저는 메모리 제조사들도 만들 정도로 시장이 커지고 있지만, 유기 인터포저는 공급망부터 조성해야한다”며 “프로세서 업체들의 강한 의지가 아니고선 규격화될 가능성이 낮다”고 설명했다.